
Soil Data Analysis with Python
Project Introduction:
"Hello there! Welcome to the soil data analysis project page. This project was designed to use various soil data for analysis to improve agriculture and better manage soil resources. The main goal is to predict soil characteristics like pH, humidity, nitrogen (N), phosphorus (P), and potassium (K) levels using machine learning models. If you're like me and passionate about agriculture and the environment, this project is a great way to get started with data analysis!"

How It Works
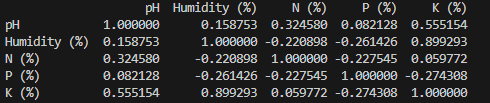
"First of all, the data collected from various soil samples includes information such as geographic coordinates, soil type, pH, humidity, and levels of nitrogen, phosphorus, and potassium. We analyzed this data using Python and libraries like Pandas and Scikit-learn. Initially, we preprocessed the data to ensure that we had clean and suitable information for modeling.
Next, we used regression models to predict various soil characteristics. The results were fascinating! We can now predict soil conditions based on the collected data."


Models and Algorithms Used
"For this project, we used linear regression algorithms to understand the relationships between different soil properties. We divided the data into training and testing sets to train our models and then evaluated their performance. After training, we compared the model predictions with the actual values to assess the error rates. The results showed that the model is quite accurate in predicting soil characteristics."
How You Can Use This Project
"You can easily run this project on your own system! Simply input your soil data in the required format, and with the provided code from GitHub, you can generate predictions about your soil conditions. If you have any questions or need assistance, feel free to reach out to me. I'm here to help!"
if you don't have GitHub account, here you are!!
